Python Coerce Utf8 to Ascii Read File
A Guide to Unicode, UTF-viii and Strings in Python
Permit's take a tour on essential concepts of strings that will have your understanding to side by side level.
![]()
Strings are i of the most mutual information types in Python. They are used to bargain with text data of whatever kind. The field of Natural Language Processing is built on superlative of text and string processing of some kind. Information technology is important to know virtually how strings work in Python. Strings are normally easy to deal with when they are made up of English ASCII characters, but "problems" appear when we enter into not-ASCII characters — which are becoming increasingly common in the world today esp. with advent of emojis etc.

Many pro g rammers use encode and decode with strings in hopes of removing the dreaded UnicodeDecodeError — hopefully, this web log will help you overcome the dread about dealing with strings. Beneath I am going to take a Q and A format to really get to the answers to the questions yous might have, and which I also had earlier I started learning about strings.
1. What are strings made of?
In Python (2 or 3), strings can either be represented in bytes or unicode lawmaking points.
Byte is a unit of measurement of information that is built of 8 bits — bytes are used to store all files in a difficult disk. And then all of the CSVs and JSON files on your computer are built of bytes. We can all concur that we need bytes, just then what virtually unicode code points?
We will get to them in the next question.
2. What is Unicode, and unicode lawmaking points?
While reading bytes from a file, a reader needs to know what those bytes hateful. And then if you write a JSON file and ship it over to your friend, your friend would demand to know how to bargain with the bytes in your JSON file. For the kickoff xx years or so of computing, upper and lower example English characters, some punctuations and digits were plenty. These were all encoded into a 127 symbol list called ASCII. seven $.25 of information or 1 byte is enough to encode every English language grapheme. Y'all could tell your friend to decode your JSON file in ASCII encoding, and voila — she would be able to read what yous sent her.
This was cool for the initial few decades or and so, but slowly we realized that there are style more number of characters than just English characters. We tried extending 127 characters to 256 characters (via Latin-1 or ISO-8859–1) to fully utilise the 8 bit infinite — but that was not enough. We needed an international standard that we all agreed on to deal with hundreds and thousands of non-English characters.
In came Unicode!
Unicode is international standard where a mapping of private characters and a unique number is maintained. As of May 2019, the well-nigh contempo version of Unicode is 12.1 which contains over 137k characters including dissimilar scripts including English language, Hindi, Chinese and Japanese, likewise every bit emojis. These 137k characters are each represented by a unicode lawmaking point. And then unicode code points refer to bodily characters that are displayed.
These code points are encoded to bytes and decoded from bytes back to code points. Examples: Unicode code point for alphabet a is U+0061, emoji 🖐 is U+1F590, and for Ω is U+03A9.
3 of the nearly popular encoding standards divers by Unicode are UTF-8, UTF-16 and UTF-32.
three. What are Unicode encodings UTF-8, UTF-16, and UTF-32?
We at present know that Unicode is an international standard that encodes every known character to a unique number. Then the adjacent question is how practice nosotros movement these unique numbers around the net? Yous already know the reply! Using bytes of information.
UTF-eight: Information technology uses 1, two, 3 or 4 bytes to encode every lawmaking point. It is backwards uniform with ASCII. All English characters just need 1 byte — which is quite efficient. We but need more bytes if we are sending non-English characters.
It is the most pop form of encoding, and is by default the encoding in Python 3. In Python 2, the default encoding is ASCII (unfortunately).
UTF-16 is variable 2 or 4 bytes. This encoding is great for Asian text as most of it can be encoded in 2 bytes each. It'south bad for English every bit all English characters also need 2 bytes here.
UTF-32 is stock-still 4 bytes. All characters are encoded in four bytes then information technology needs a lot of memory. It is non used very ofttimes.
[You can read more in this StackOverflow post.]
We need encode method to catechumen unicode lawmaking points to bytes. This will happen typically during writing string data to a CSV or JSON file for example.
Nosotros need decode method to convert bytes to unicode code points. This will typically happen during reading information from a file into strings.
iv. What data types in Python handle Unicode lawmaking points and bytes?
Every bit we discussed earlier, in Python, strings tin either be represented in bytes or unicode code points.
The main takeaways in Python are:
1. Python two uses str type to store bytes and unicode blazon to store unicode code points. All strings by default are str type — which is bytes~ And Default encoding is ASCII. And so if an incoming file is Cyrillic characters, Python 2 might fail considering ASCII will not be able to handle those Cyrillic Characters. In this instance, nosotros need to think to use decode("utf-8") during reading of files. This is inconvenient.
2. Python three came and fixed this. Strings are nevertheless str type by default but they now mean unicode code points instead — nosotros acquit what we run into. If we want to store these str type strings in files we utilize bytes blazon instead. Default encoding is UTF-eight instead of ASCII. Perfect!
5. Any code examples to compare the dissimilar data types?
Yeah, let's wait at "你好" which is Chinese for howdy. It takes six bytes to store this string made of ii unicode code points. Let'southward take the example of popularlen office to run across how things might differ in Python 2 and 3 — and things you lot need to keep note of.
>>> print(len("你好")) # Python 2 - str is bytes
6 >>> print(len(u"你好")) # Python 2 - Add together 'u' for unicode lawmaking points
2 >>> print(len("你好")) # Python three - str is unicode code points
2
So, prefixing a u in Python 2 can make a consummate divergence to your code performance correctly or not — which can be confusing! Python 3 fixed this by using unicode code points by default — so len will work as you would expect giving length of ii in the instance above.
Let's look at more examples in Python 3 for dealing with strings:
# strings is past default made of unicode code points
>>> impress(len("你好"))
ii # Manually encode a cord into bytes
>>> print(len(("你好").encode("utf-8")))
half dozen # You don't need to laissez passer an argument as default encoding is "utf-viii"
>>> impress(len(("你好").encode()))
6 # Print actual unicode code points instead of characters [Source]
>>> print(("你好").encode("unicode_escape"))
b'\\u4f60\\u597d' # Impress bytes encoded in UTF-8 for this cord
>>> print(("你好").encode())
b'\xe4\xbd\xa0\xe5\xa5\xbd'
6. It'due south a lot of information! Tin you summarize?
Certain! Let's see all we have covered so far visually.
By default in Python 3, we are on the left side in the world of Unicode code points for strings. We simply need to go back and forth with bytes while writing or reading the data. Default encoding during this conversion is UTF-eight, only other encodings can also be used. Nosotros need to know what encoder was used during the decoding procedure, otherwise nosotros might get errors or go gibberish!
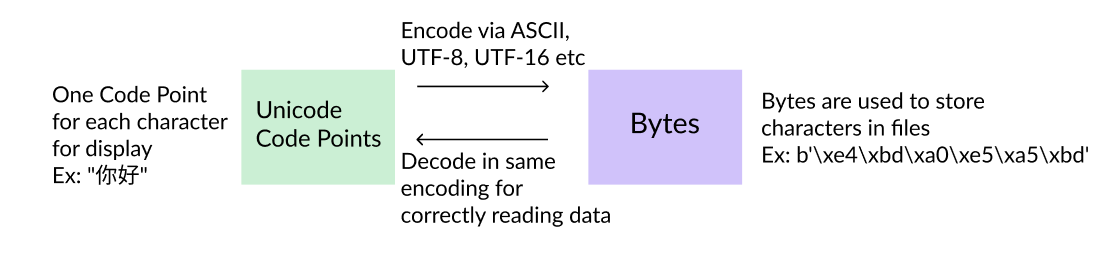
This diagram holds true for both Python 2 and Python 3! Nosotros might be gettingUnicodeDecodeErrors due to:
1) We trying to use ASCII to encode non-ASCII characters. This would happen esp. in Python two where default encoder is ASCII. Then you should explicitly encode and decode bytes using UTF-8.
ii) We might be using the wrong decoder completely. If unicode code points were encoded in UTF-16 instead of UTF-8, y'all might run into bytes that are gibberish in UTF-viii country. So UTF-8 decoder might fail completely to sympathise the bytes.
A proficient practice is to decode your bytes in UTF-8 (or an encoder that was used to create those bytes) as soon equally they are loaded from a file. Run your processing on unicode code points through your Python code, then write back into bytes into a file using UTF-eight encoder in the end. This is called Unicode Sandwich. Read/watch the excellent talk past Ned Batchelder (@nedbat) about this.
If you want to add more data about strings in Python, please mention in the comments below every bit it will assist others. This concludes my web log on the guide to Unicode, UTF-8 and strings. Proficient luck in your own explorations with text!
PS, check out my new podcast! Information technology's called "The Data Life Podcast" where I talk about like topics. In a recent episode I talked about Why Pandas is the new Excel. You tin can listen to the podcast hither or wherever yous listen to your podcasts.

If you take any questions, driblet me a note at my LinkedIn contour. Thanks for reading!
Source: https://towardsdatascience.com/a-guide-to-unicode-utf-8-and-strings-in-python-757a232db95c
{kind=link}
ارسال یک نظر for "Python Coerce Utf8 to Ascii Read File"